Image Details
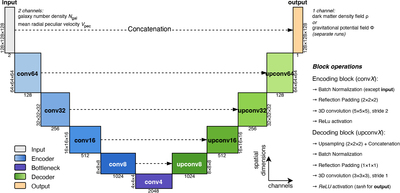
Caption: Figure 4.
Architecture of the 3D V-Net used in this work. The input has two channels: galaxy number density Ngal and mean radial peculiar velocity Vpec. Spatial features are encoded via convolutional layers (convX), followed by a bottleneck layer and a symmetric decoder path (upconvX) with skip connections. The output is a single channel representing either the dark matter density field ρ or the gravitational potential field ϕ, trained separately using the same input and architecture. The width and height of each block indicate the number of channels (below) and spatial dimensions (left), respectively. The detailed suboperations within each encoding and decoding block are summarized on the right.
Other Images in This Article







Show More
Copyright and Terms & Conditions
© 2026. The Author(s). Published by the American Astronomical Society.