Image Details
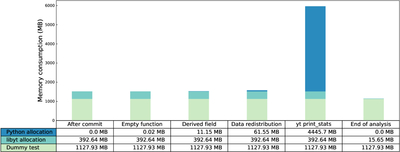
Caption: Figure 12.
The average per-process memory usage across several libyt in situ analysis stages, including: after committing the simulation settings (After commit), while running an empty Python function (Empty function), while generating 5000 grids of derived field data (Derived field), while redistributing 20,000 grids (Data redistribution), run yt operation print_stats (yt print_stats), and after freeing every resource allocated for this round of analysis (End of analysis). The dummy test runs on four MPI processes and consists of a total of 2 × 106 grids, each containing one field of size 83 with data type float. libyt takes ∼0.2 KB to store a grid’s metadata (e.g., grid level and field data pointers). When generating derived field data or performing data redistribution using libyt, the memory consumption is controllable if data chunking is done wisely. The Python memory allocation depends solely on the Python code executed, and libyt has no control. For example, yt operation print_stats takes 4 times more memory than the dummy test itself. At the end of libyt in situ analysis, because libyt needs to store other background resources, it still occupies some memory and will not return to zero.
Other Images in This Article




Show More
Copyright and Terms & Conditions
© 2026. The Author(s). Published by the American Astronomical Society.