Image Details
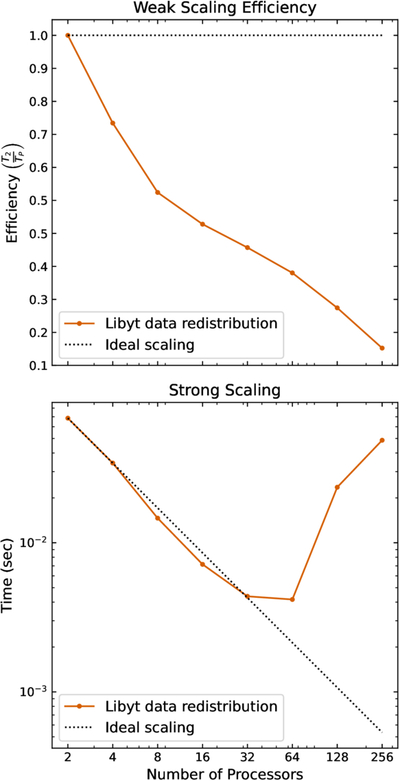
Caption: Figure 10.
Weak scaling efficiency (upper) and strong scaling (lower) of the libyt data redistribution process. Each MPI process runs on a single core and occupies a computing node (two processes per node at 256 processors). The tests redistribute randomly selected 83 floating-point grids among processes. In weak scaling, each process fetches 5000 grids (∼10 MB), maintaining a constant workload per process; efficiency declines approximately linearly with ﹩\mathrm{log}(﹩processor count) due to the synchronization overhead. In strong scaling, a fixed 20,000 grids (∼40 MB) are redistributed evenly among processes; performance follows the ideal trend up to 32 processors, after which execution time increases as communication overhead dominates, partly because the reduced computational workload per process becomes insufficient to offset the communication cost.
Other Images in This Article




Show More
Copyright and Terms & Conditions
© 2026. The Author(s). Published by the American Astronomical Society.