Image Details
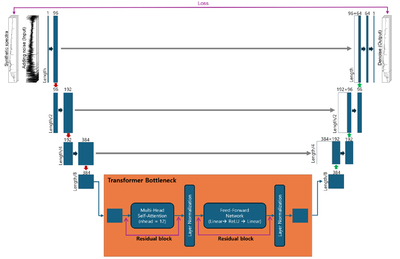
Caption: Figure 1.
Schematic of the EUT architecture. The network takes a synthetic galaxy spectrum and a noise-added realization as input (left) and predicts a denoised spectrum (right); the loss is evaluated against the corresponding noise-free spectrum. The encoder (blue, left) has three 1D convolutional stages with channel dimensions 1 → 96 → 192 → 384. Each stage applies a convolution (kernel size =7), instance normalization, and ReLU activation, followed by max pooling that halves the sequence length (L → L/2 → L/4 → L/8). The compressed feature sequence is passed to a transformer bottleneck (orange), where fixed sinusoidal positional encodings and Nlayer = 8 transformer blocks—multihead self-attention (nhead = 12) and position-wise feed-forward networks with residual connections and layer normalization—model long-range correlations along the wavelength axis. The decoder (blue, right) upsamples back to the original length using linear interpolation and convolution, with channel dimensions 384 → 192 → 96 → 64, followed by a final one-channel projection. Gray arrows indicate skip connections that concatenate encoder and decoder feature maps at matched resolutions, helping preserve narrow absorption-line structure in the denoised output.
Other Images in This Article






Copyright and Terms & Conditions
© 2026. The Author(s). Published by the American Astronomical Society.