Image Details
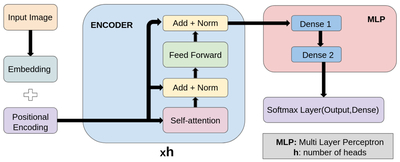
Caption: Figure 10.
This figure presents the architecture of our ViT model. Input images are divided into patches, embedded, and subsequently augmented with positional encodings. The encoder processes these embeddings using self-attention mechanisms and a multilayer perceptron (MLP). The final output is a parameter likelihood vector generated via a softmax layer.
Other Images in This Article





Show More
Copyright and Terms & Conditions
© 2025. The Author(s). Published by the American Astronomical Society.
Copyright ©
2025 Astronomy Image Explorer. All Rights Reserved.