Image Details
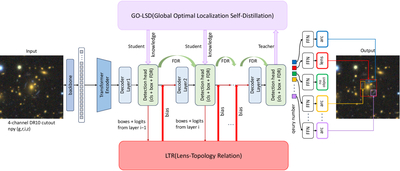
Caption: Figure 6.
Schematic overview of the proposed GL-D-FINE detector. A convolutional backbone and a transformer encoder process the multiband input cutouts into a sequence of features. The LTR module (red) uses boxes from layers i − 1 and i together with class logits from layer i to produce topology-aware attention biases that guide the subsequent decoder layer (i + 1). GO-LSD (purple) and FDR (part of the detection head) are employed for enhanced localization. By explicitly modeling geometric dependencies, the architecture allows lens-system and arc queries to be refined jointly.
Other Images in This Article





Copyright and Terms & Conditions
© 2026. The Author(s). Published by the American Astronomical Society.
Copyright ©
2026 Astronomy Image Explorer. All Rights Reserved.