Image Details
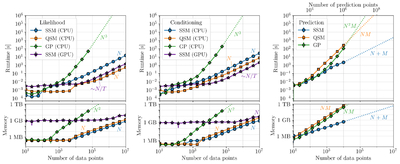
Caption: Figure 4.
Runtime and memory benchmarking comparing the performance on instantaneous data of the full/dense GP solution (i.e., Equation (4), as in tinygp, green diamonds), using QSM algebra (also via tinygp, orange squares), and our implementation of the sequential SSM solver (smolgp, blue circles); these three cases were all tested on a CPU because their performance on a GPU was degraded. Dashed lines trace the theoretical scaling from the largest value tested. In all cases, the top panel shows the wall-clock timed average of five runs, while the bottom shows the peak memory usage during the function execution. The purple stars show the parallel SSM solver (SG21 as implemented in smolgp) as tested on a NVIDIA RTX 6000 Ada GPU running CUDA v12.8. Left: Results for the log-likelihood as a function of N data points. Middle: Results for conditioning at the N data points, including initialization. Right: Results for conditioning on N data points and then predicting at M = 100N test points, to simulate a typical high-resolution prediction scenario. Takeaway: The SSM shares the linear runtime scaling as QSMs but is typically more memory efficient (especially for predictions). Computing the likelihood is faster in the QSM framework, although for conditioning, the best runtime performance is achieved by the parallel SSM (with high memory overhead on a GPU).
Other Images in This Article




Copyright and Terms & Conditions
© 2026. The Author(s). Published by the American Astronomical Society.