Image Details
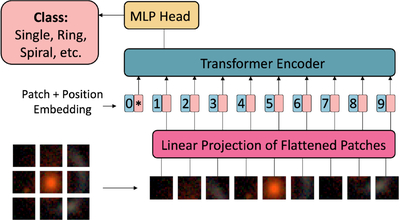
Caption: Figure 5.
Architecture of the Vision Transformer (ViT; A. Dosovitskiy et al. 2021). The input image is divided into fixed-size image sections, which are linearly embedded and combined with position embeddings. These embeddings are then processed by a Transformer Encoder, which applies multiple self-attention mechanisms. The output is finally fed into a classification head to predict the input image’s class based on the training categories.
Other Images in This Article






Show More
Copyright and Terms & Conditions
© 2026. The Author(s). Published by the American Astronomical Society.
Copyright ©
2026 Astronomy Image Explorer. All Rights Reserved.