Image Details
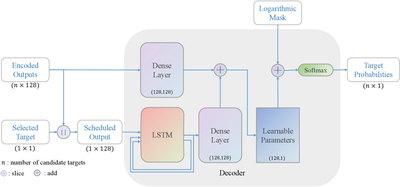
Caption: Figure 3.
The decoder comprises an LSTM module, two dense layers, and a learnable parameters set. The LSTM takes the outputs of the encoder as input to form a hybrid context to capture the sequence states. The outputs of the two dense layers are added, and the sum is sent to the learnable parameters block. After adding the result with the logarithmic mask, the softmax layer calculates the probability distribution of unscheduled targets.
Other Images in This Article




Copyright and Terms & Conditions
© 2025. The Author(s). Published by the American Astronomical Society.
Copyright ©
2026 Astronomy Image Explorer. All Rights Reserved.