Image Details
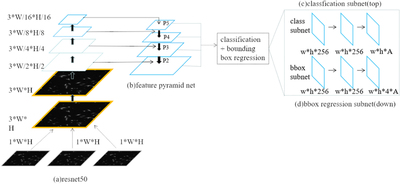
Caption: Figure 1.
Architecture of the Faster R-CNN used in this paper. An input image includes three channels and the image in each channel is the same astronomical image. The input image passes into the first convolutional layer, which has three convolution layers with a stride of one and and a convolution kernel of 3 × 3 to process each channel of the input image. Then the output of the first convolutional layer will be put into the feature pyramid network for feature extraction. In the feature pyramid network, feature maps from the P2 layer are used as features of the images for each candidate. These feature maps will be used for classification by comparison between the features of different categories and they will also be used for position regression through bounding box regression. The Rectified Linear Unit (ReLU) function, which uses the rectifier activation function ﹩\max (0,n)﹩ to evaluate outputs of previous layers, is used as activation functions for all five hidden layers. In this figure, W and H stand for the size of original image and w and h stand for the size of the candidate image. The blue boxes stand for the different convolutional stages and the shape of these layers is shown beside these boxes.
Other Images in This Article





Copyright and Terms & Conditions
© 2020. The American Astronomical Society. All rights reserved.