Image Details
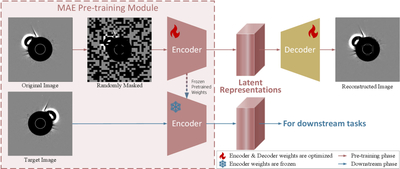
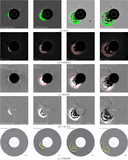
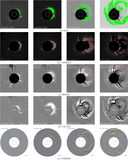
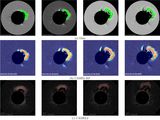
Caption: Figure 2.
Architecture of the MAE for self-supervised pretraining. During pretraining (the top branch), 60% of patches from the input image are masked. The encoder processes the unmasked patches to build a latent representation, which the decoder uses to reconstruct the original image. In the next CME detection stage (the bottom branch), the pretrained encoder generates a latent representation from a full image to support downstream CME localization and segmentation tasks.
Other Images in This Article




Copyright and Terms & Conditions
© 2026. The Author(s). Published by the American Astronomical Society.
Copyright ©
2026 Astronomy Image Explorer. All Rights Reserved.