Image Details
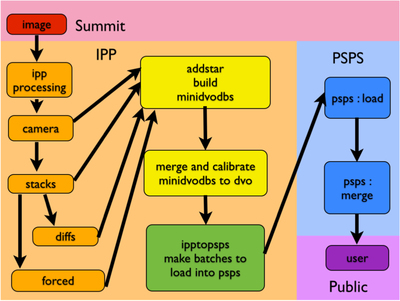
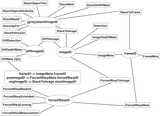
Caption: Figure 1.
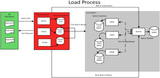
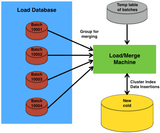
An overview of the steps necessary to create publicly accessible Pan-STARRS1 data. The first step is to take exposures from the summit, process them via the image processing pipeline (IPP), ingest the data into the PSPS, and then provide public access to the user. The IPP has many processing steps; not all are shown here. The camera, stacks, difference images, and forced photometry stages produce binary catalog FITS files, which are the foundation of building the DVO database, which is then calibrated. The final step of IPP processing is to use IppToPsps to generate small batches of data in the appropriate database schema to be ingested into PSPS. This paper primarily focuses on the PSPS and the database schema. The other steps are explained in enough detail to describe known and potential sources of inconsistencies within the database.
Other Images in This Article

Copyright and Terms & Conditions
© 2020. The American Astronomical Society. All rights reserved.