Image Details
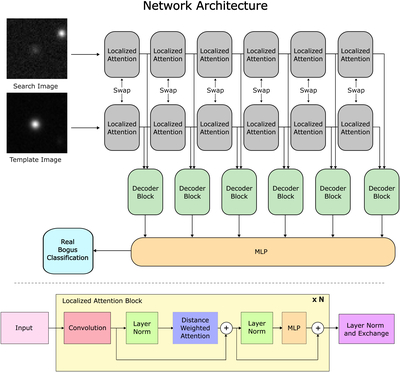
Caption: Figure 2.
Network architecture of the real–bogus classifier used in this work. (Above) Input images are passed through six localized attention blocks with shared weights to extract salient features. Three distance-weighted localized attention steps are performed in each block. The features are forwarded to decoder blocks and the MLP layer for binary prediction. (Below) Inner working of localized attention modules. In our work, we use N = 3 blocks for each module.
Other Images in This Article



Copyright and Terms & Conditions
© 2026. The Author(s). Published by the American Astronomical Society.
Copyright ©
2026 Astronomy Image Explorer. All Rights Reserved.